Contents
1. Crawled RDF Data
The dump of all the Linked Data that we crawled for our experiments from the Web can be downloaded here. The file contains 188 mio. triples and has a size of 2.6 GB zipped.
2. Crawled Vocabulary Term Definitions
The vocabulary definitions crawled to test the dereferencability and interconnectivity of vocabularies can be downloaded here. It contains 8.4 mio triples and has as size of 122 MB zipped.
3. Dataset Metadata
We provide all the metadata that we have generated to describe the data sets in the form of a dataset catalog (link auf catalog) and as a single RDF file for download. The metadata dump can be downloaded here.
4. Data Catalog and Interactive Statistics
In order to make it easier to explore the generated metadata, we have loaded it into a Data Catalog which represents the metadata in the form of tags.
We also offer a webpage which allows you to explore the datasets behind each statistical result.
5. Tables
Tables that have been aggregated from the crawled data and which are the basis of our analysis are available for download. They include:
- Datasets and their categories (Download)
- Not crawlable, but online datasets from datahub.io (Download)
- Datasets and their in- and outdegree (Download)
- Vocabularies used by datasets (Download)
- Proprietary vocabularies and their quota of dereferencable terms (Download)
- Proprietary vocabularies and their links to other vocabularies (Download)
- Datasets that provide provenance information (Download) and the provenance vocabularies used (Download)
- Datasets that provide license information (Download) and the license predicates used (Download)
- Datasets that provide dataset-level metadata (Download)
6. LOD Cloud Diagram
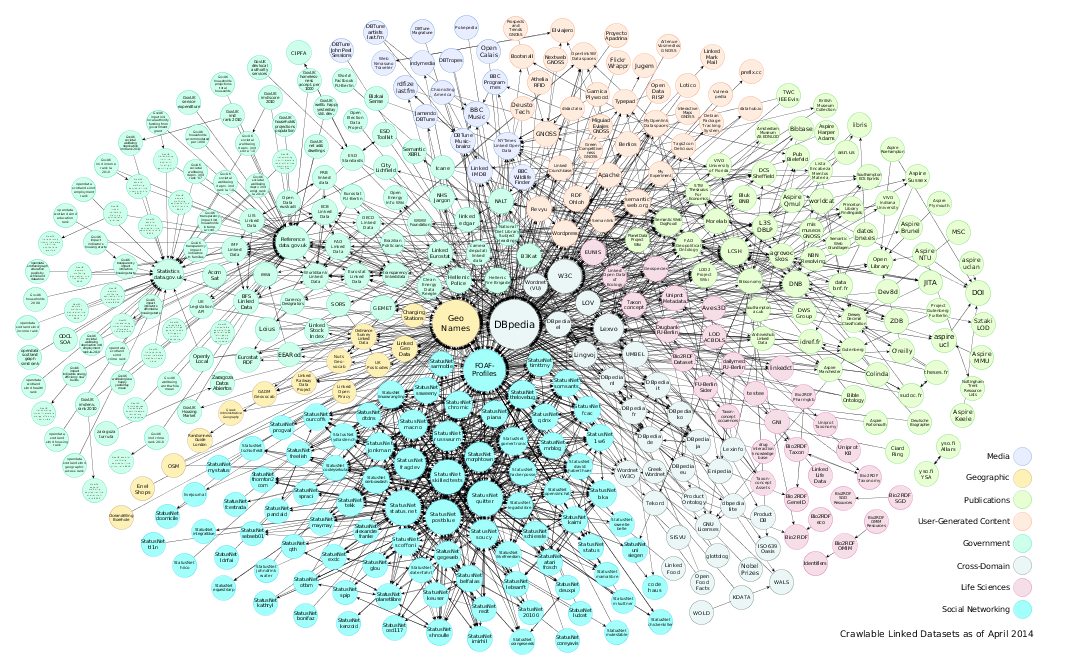
A svg version of the diagram can be downloaded here.
{kind=link}
7. Code
LDSpider was used for crawling the datasets.
The seed list can be downloaded here. It contains 560 thousand seeds and has a packed size of 4.1 MB.
The sourcecode used for analyzing the crawl can be downloaded here. It has a packed size of 8.7 KB.
8. Credits
The work was supported by the EU research project PlanetData.
